
While this reference aims to provide a thorough breakdown of the various HTML elements and their respective attributes, you also need to understand how these items fit into the bigger picture. A web page is structured as follows.
Key Takeaways
- The basic structure of a web page includes the Doctype, the HTML element, and the head and body sections. The Doctype provides information about the markup language, the HTML element is the root of the document tree, the head contains metadata, and the body contains the visible content.
- The head and body sections of a web page are divided into various elements like headers, paragraphs, links, and images, which are represented by HTML tags. These elements and their arrangement contribute to the structure and functionality of the web page.
- A well-structured web page is crucial for both user experience and search engine optimization, making it essential for developers to understand and use HTML effectively. Other languages like CSS and JavaScript can further enhance the structure, design, and interactivity of a web page.
The Doctype
The first item to appear in the source code of a web page is the doctype declaration. This provides the web browser (or other user agent) with information about the type of markup language in which the page is written, which may or may not affect the way the browser renders the content. It may look a little scary at first glance, but the good news is that most WYSIWYG web editors will create the doctype for you automatically after you’ve selected from a dialog the type of document you’re creating. If you aren’t using a WYSIWYG web editing package, you can refer to the list of doctypes contained in this reference and copy the one you want to use.
The doctype looks like this (as seen in the context of a very simple HTML 4.01 page without any content):
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01//EN""https://www.w3.org/TR/html4/strict.dtd"><html><head><title>Page title</title></head><body></body></html>
In the example above, the doctype relates to HTML 4.01 Strict. In this reference, you’ll see examples ofHTML 4.01 and also XHTfML 1.0 and 1.1, identified as such. While many of the elements and attributes may have the same names, there are some distinct syntactic differences between the various versions of HTML andXHTML. You can find out more about this in the sections entitled HTML Versus XHTML and HTML and XHTML Syntax.
The Document Tree
A web page could be considered as a document tree that can contain any number of branches.There are rules as to what items each branch can contain (and these are detailed in each element’s reference in the “Contains” and “Contained by”sections). To understand the concept of a document tree, it’s useful to consider a simple web page with typical content features alongside its tree view, as shown in Figure 1.
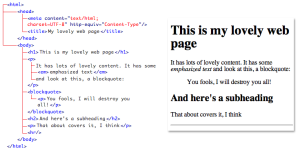
If we look at this comparison, we can see that thehtml element in fact contains two elements:head and body.head has two subbranches—a metaelement and a title. The bodyelement contains a number of headings, paragraphs, and ablock quote.
Note that there’s some symmetry in the way the tags are opened and closed. For example, the paragraph that reads, “It has lots of lovely content …” contains three text nodes, the second of which is wrapped in an em element (for emphasis). The paragraph is closed after the content has ended, and before the next element in the tree begins (in this case, it’s ablockquote); placing the closing </p>after the blockquote would break the tree’s structure.
html
Immediately after the doctype comes the htmlelement—this is the root element of the document tree and everything that follows is a descendant of that root element.
If the root element exists within the context of a document that’s identified by its doctype as XHTML, then the html element also requires an xmlns (XML Namespace) attribute (this isn’t needed for HTML documents):
<html xmlns="https://www.w3.org/1999/xhtml">
Here’s an example of an XHTML transitional page:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN""https://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"><html xmlns="https://www.w3.org/1999/xhtml"><head><title>Page title</title></head><body></body></html>
Thehtml element breaks the document into two mainsections: the head and the body.
head
The head element contains metadata—information that describes the document itself, or associates it with related resources, such as scripts and style sheets.
The simple example below contains the compulsory title element, which represents the document’s title or name—essentially, it identifies what this document is. The content inside the title may be used to provide a heading that appears in the browser’s title bar, and when the user saves the page as a favorite. It’s also a very important piece of information in terms of providing a meaningful summary of the page for the search engines, which display the titlecontent in the search results. Here’s the title inaction:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN""https://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"><html xmlns="https://www.w3.org/1999/xhtml"><head><title>Page title</title></head><body></body></html>
In addition to thetitle element, the head may also contain:
-
defines baseURLs for links or resources on the page, and target windows in which to open linked content
-
refers to are source of some kind, most often to a style sheet that provides instructions about how to style the various elements on the webpage
-
provides additional information about the page; for example, which character encoding the page uses, a summary of the page’s content, instructions to search engines about whether or not to index content, and soon
-
represents a generic, multipurpose container for a media object
-
used either to embed or refer to an external script
-
provides an area for defining embedded (page-specific) CSS styles
All of these elements are optional and can appear in any order within the head. Note that none of the elements listed here actually appear on the rendered page, but they are used to affect the content on the page, all of which is defined inside thebody element.
body
This is where the bulk of the page is contained. Everything that you can see in the browser window (or viewport) is contained inside this element, including paragraphs, lists, links, images, tables, and more. The body element has some unique attributes of its own, all of which are now deprecated, but aside from that, there’s little to say about this element. How the page looks will depend entirely upon the content that you decide to fill it with; refer to the alphabetical listing of all HTML elements to ascertain what these contents might be.
Frequently Asked Questions about Basic Structure of a Web Page
What is the importance of a well-structured web page?
A well-structured web page is crucial for both user experience and search engine optimization. For users, a well-structured page allows easy navigation, quick understanding of the content, and a smooth browsing experience. For search engines, a good structure makes it easier to crawl and index the page, which can improve its ranking in search results. Moreover, a well-structured page is more likely to be shared and linked to, further boosting its visibility and reach.
How does HTML contribute to the structure of a web page?
HTML, or HyperText Markup Language, is the backbone of any web page. It provides the basic structure of the page, divided into elements like headers, paragraphs, links, and images. These elements are represented by tags, which tell the browser how to display the content. Understanding and using HTML effectively is key to creating a well-structured web page.
What are the key elements of a web page structure?
The key elements of a web page structure include the DOCTYPE declaration, HTML tags, head and body sections, and various content elements like headers, paragraphs, links, and images. The DOCTYPE declaration specifies the version of HTML used, while the HTML tags enclose all the content of the page. The head section contains meta-information about the page, and the body section contains the actual content.
How does CSS contribute to the structure of a web page?
CSS, or Cascading Style Sheets, is used to style and layout web pages. It controls how HTML elements are displayed on the screen, allowing developers to create visually appealing pages with consistent design. While HTML provides the basic structure, CSS enhances it with colors, fonts, spacing, and other visual elements.
What is the role of JavaScript in a web page structure?
JavaScript is a programming language used to make web pages interactive. It can manipulate HTML elements and CSS styles, respond to user actions, and even fetch and send data to a server. While not directly involved in the basic structure of a web page, JavaScript greatly enhances its functionality and user experience.
How can I improve the structure of my web page for SEO?
Improving the structure of your web page for SEO involves several steps. First, ensure that your HTML is clean and error-free, with clear and logical organization. Use header tags to highlight the hierarchy of your content, and alt tags for images. Second, make your page easy to navigate, with a clear menu and internal links. Finally, optimize your page speed, as slow pages can hurt your ranking.
What is the difference between a static and a dynamic web page structure?
A static web page structure is one where the content and layout are fixed, and the same for every user. It is created using only HTML and CSS. A dynamic web page structure, on the other hand, can change based on user interaction or other factors. It is created using server-side scripting languages like PHP or ASP, in addition to HTML and CSS.
How does responsive design affect the structure of a web page?
Responsive design is a technique that allows a web page to adjust its layout based on the screen size and orientation of the device it’s viewed on. This involves flexible grids and layouts, images, and CSS media queries. With responsive design, the structure of a web page becomes more flexible and adaptable, improving the user experience on different devices.
What is the role of a sitemap in a web page structure?
A sitemap is a file that lists all the pages of a website, helping search engines understand its structure and content. It can improve the crawling of your site, especially if it’s large or has a complex structure. A sitemap can also provide valuable metadata about your pages, like when they were last updated and how important they are.
How can I test the structure of my web page?
There are several tools and techniques to test the structure of your web page. You can use a validator to check your HTML and CSS for errors and inconsistencies. You can also use a crawler to simulate how search engines navigate your site. User testing, either through direct observation or using analytics tools, can provide valuable feedback on the usability and navigation of your page.
Ophelie was Head of Content at SitePoint and SitePoint Premium. She also runs ophelielechat.com.


Published in
·Android·App Development·iOS·JavaScript·Mobile·Mobile Web Development·Tools & Libraries·September 23, 2014

